
Todos los tools de hiring ahora dicen “AI-powered”.
¿La realidad? El 90% usa ChatGPT con un prompt genérico.
Y eso es un problema. Porque en psychometrics, domain expertise no es un nice-to-have — es la diferencia entre insights accionables y análisis superficial.
En este post te muestro exactamente qué diferencia a una IA especializada de una genérica. Con ejemplos reales. Sin marketing fluff.
El Problema con “AI-Powered” Genérico
La industria de HR Tech tiene un problema: todos agregan “Powered by GPT-4” a su landing page y lo llaman innovación.
Pero usar ChatGPT para analizar resultados psicométricos es como usar Google Translate para traducir poesía. Funciona técnicamente, pero pierde todo el contexto y los matices.
Por Qué ChatGPT Falla en Psychometrics
1. No entiende el scoring matemático
OCEAN no es IA — es ciencia. Los scores se calculan con fórmulas validadas en 15,000+ estudios. ChatGPT no “sabe” qué significa que Conscientiousness=45 vs 85 en el contexto de un Product Manager en una startup early-stage.
2. No tiene contexto organizacional
Un candidato con alto Openness (85) puede ser excelente para una startup innovando en IA, pero terrible para una empresa enterprise con procesos establecidos. ChatGPT no tiene este contexto.
3. Pattern matching sin comprensión
ChatGPT ve “alta extraversión” y genera texto genérico sobre “roles de cara al cliente”. Pero no entiende que un Software Engineer con E=80 puede ser problemático en equipos que valoran deep work.
4. Bias amplification
Los LLMs genéricos reproducen sesgos históricos de sus datos de entrenamiento. Sin fine-tuning específico, perpetúan estereotipos problemáticos (ej: “mujeres con alta agreeableness son mejores para HR”).
Ejemplo real: Le pedimos a ChatGPT que analice un profile OCEAN para un rol de Senior Engineer.
Su respuesta: “Este candidato muestra alta apertura y extraversión, lo cual es ideal para roles creativos y de cara al cliente.”
El problema: No mencionó que C=45 es una RED FLAG para Senior Engineers. No consideró el rol específico. No dio acciones concretas.
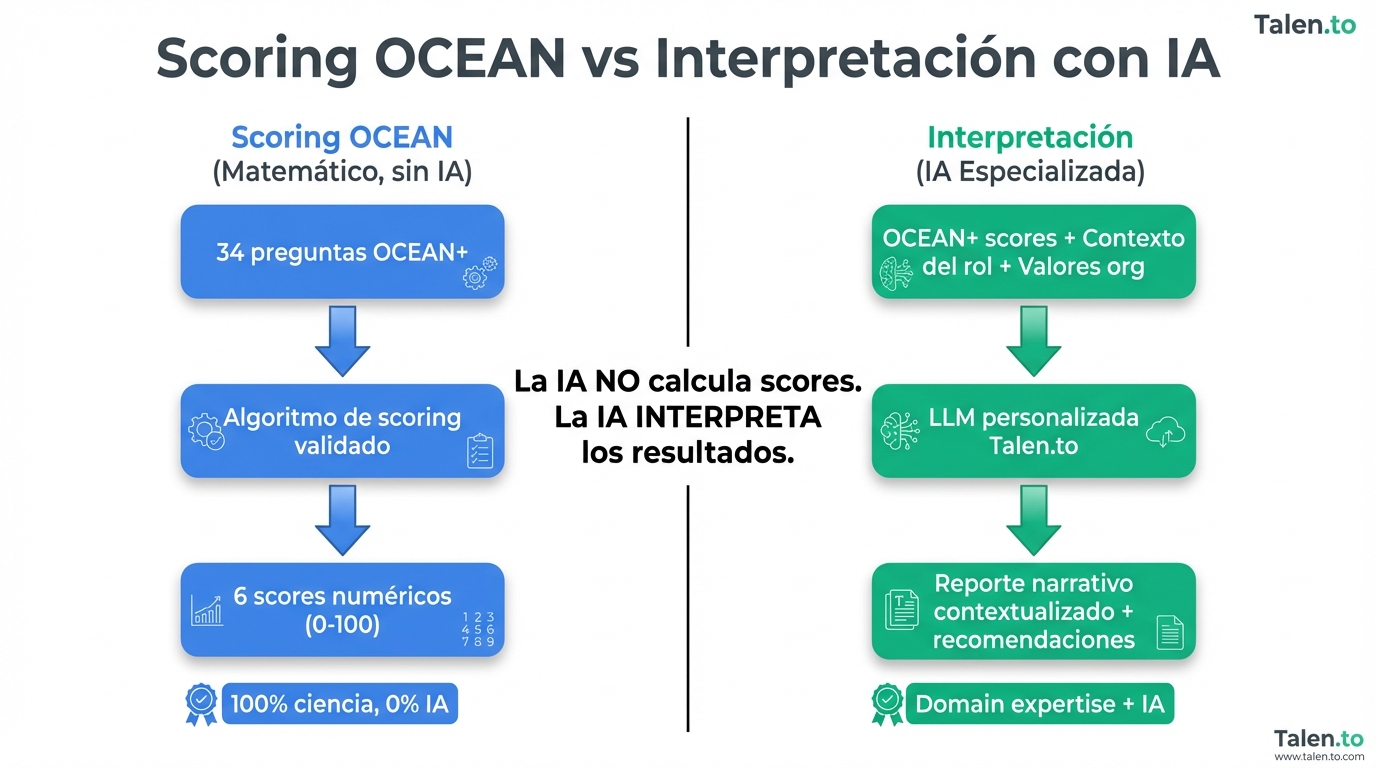
Qué Hace Diferente una LLM Especializada
En Talen.to, no usamos ChatGPT con un prompt fancy. Tenemos una LLM entrenada específicamente en psychometric analysis.
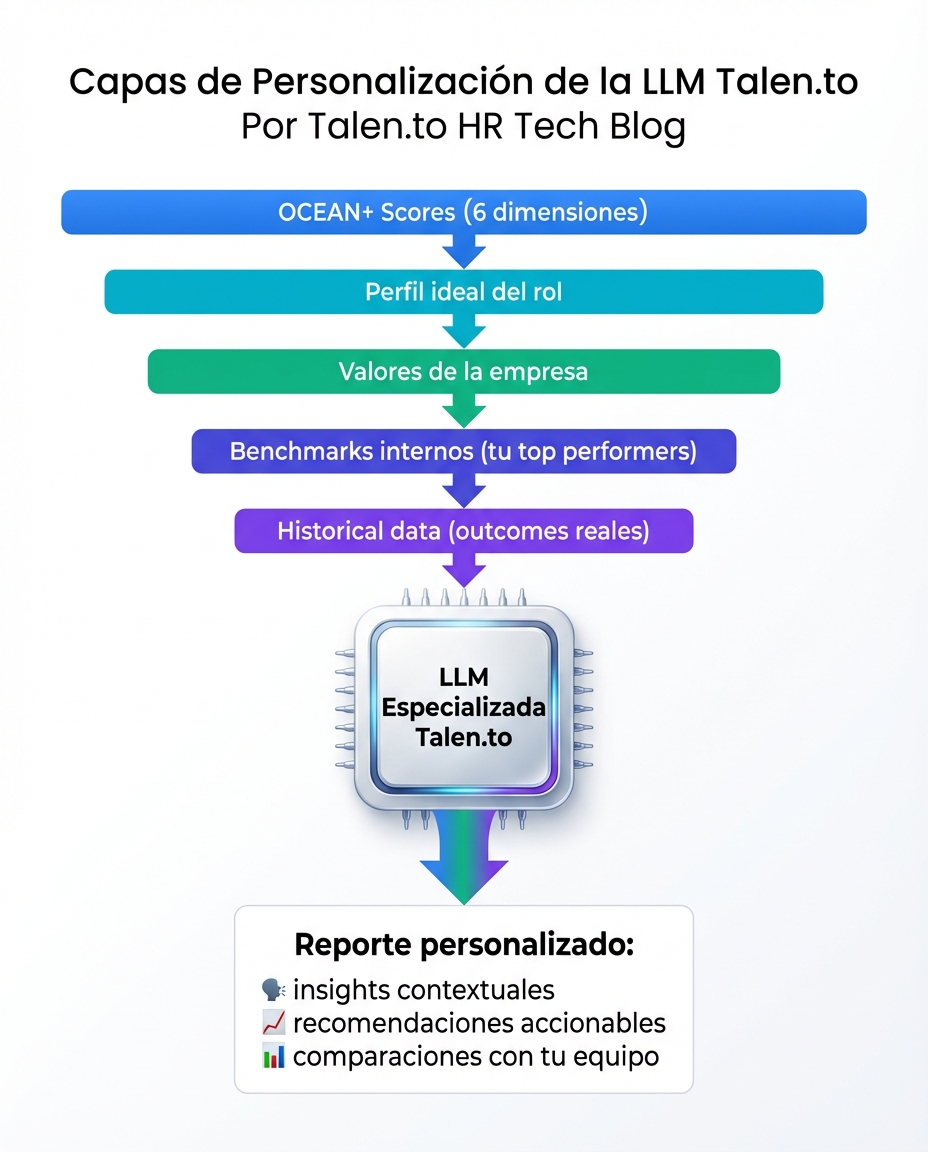
Tres Capas de Especialización
1. Domain Training
Entrenamos el modelo con:
- Miles de evaluaciones reales + correlaciones con performance
- Research papers de organizational psychology
- Outcomes reales (retención, performance ratings, promociones)
El resultado: La IA “entiende” qué significa C=45 vs C=85 en diferentes contextos.
2. Contextual Adaptation
Cada organización es única:
- Una startup tech valora innovación > estabilidad
- Un banco enterprise valora confiabilidad > disrupción
- Una agencia creativa valora colaboración > autonomía
Nuestra LLM se adapta a tu contexto específico: industry, stage, cultura, valores.
3. Feedback Loops
Aprendemos de outcomes reales:
- Qué profiles tuvieron éxito en tu organización
- Qué dimensiones predicen mejor performance en tu industria
- Qué trade-offs funcionan para tu cultura
Con cada evaluación, el modelo se vuelve más preciso para tu caso específico.
Clarificación clave: El scoring OCEAN sigue siendo 100% matemático y científico. La IA NO calcula scores — eso lo hace el algoritmo validado científicamente.
La IA entra DESPUÉS del scoring, para:
- Interpretar los resultados en contexto
- Generar insights accionables
- Detectar trade-offs y riesgos
- Comparar con benchmarks relevantes
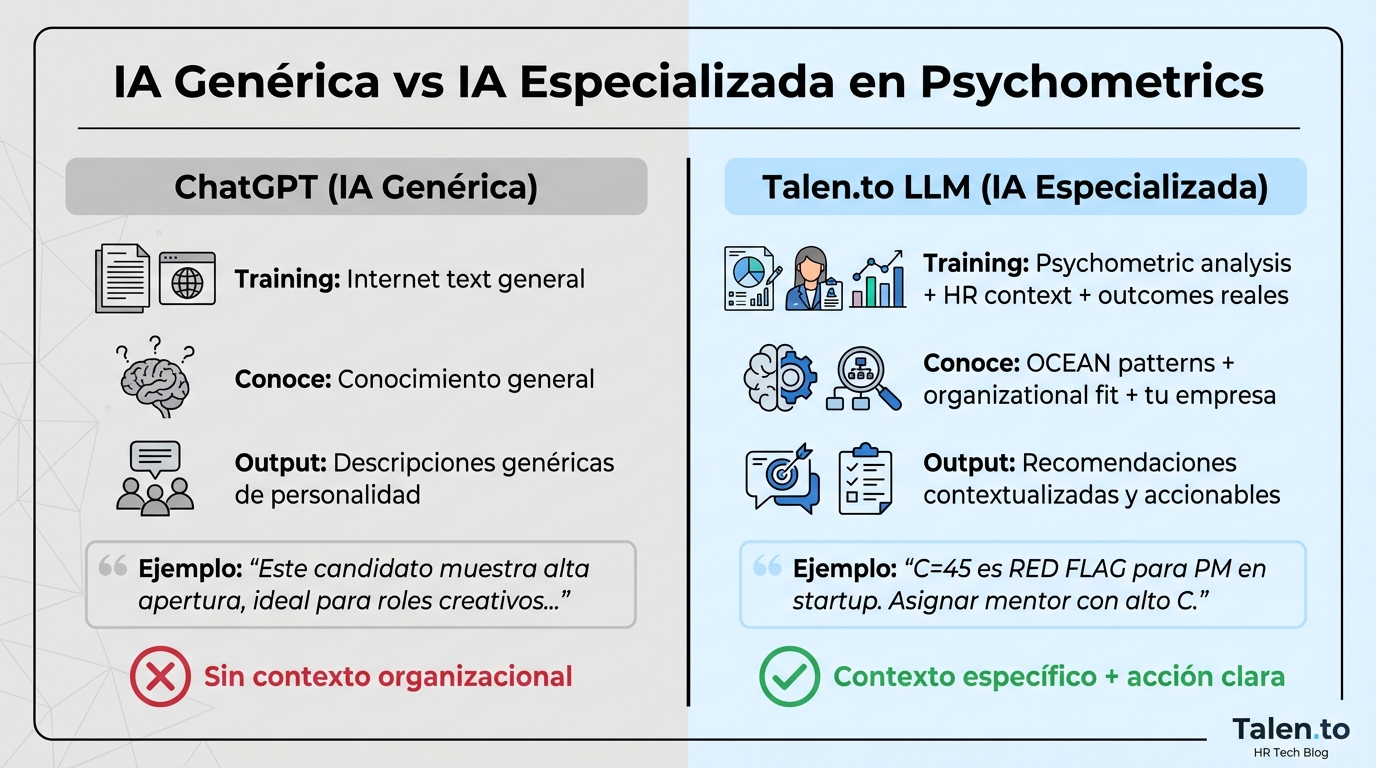
Side-by-Side: ChatGPT vs Talen.to LLM
Probemos con un caso real. Mismo OCEAN profile, dos análisis.
Input: Candidato para Product Manager en startup early-stage (50 personas, Series A)
OCEAN Profile:
- Openness: 75
- Conscientiousness: 45
- Extraversion: 80
- Agreeableness: 60
- Estabilidad Emocional: 70
- Engagement Relacional: 85
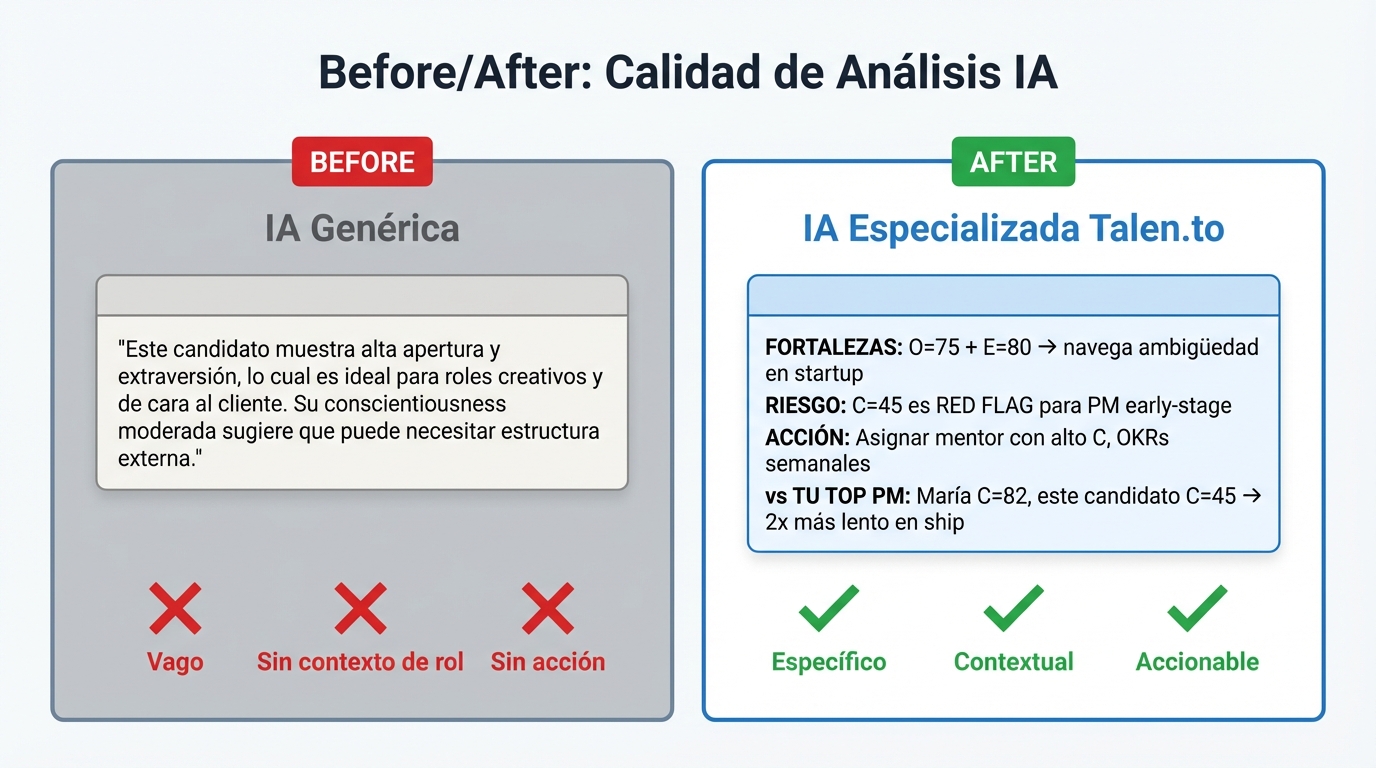
ChatGPT Analysis (IA genérica)
“Este candidato muestra alta apertura y extraversión, lo cual es ideal para roles creativos y de cara al cliente. Su conscientiousness moderada sugiere que puede necesitar estructura externa. Se recomienda evaluar fit para posiciones que valoren innovación y trabajo en equipo.”
Problemas con este análisis:
❌ No considera el rol específico (Product Manager)
❌ No entiende el stage (early-stage = execution obsession)
❌ No menciona EE/ER (dimensiones únicas de OCEAN+)
❌ “Conscientiousness moderada” suena benigno — pero C=45 puede ser FATAL
❌ Recomendación vaga sin acción clara
❌ No compara con benchmarks relevantes
Talen.to LLM Analysis (IA especializada)
Para el rol de Product Manager en startup early-stage:
FORTALEZAS CRÍTICAS:
- Alta apertura (75) + alta extraversión (80) = capacidad de navegar ambigüedad y evangelizar visión externamente
- Engagement Relacional excepcional (85) = puede traducir feedback de clientes en features sin perder perspectiva técnica
RIESGOS A MITIGAR:
- Conscientiousness moderada-baja (45) es RED FLAG para este stage. Startups early-stage necesitan execution obsession. Sin estructura organizacional establecida, este score sugiere riesgo de:
- Features anunciadas pero no shipped a tiempo
- Documentación incompleta
- Priorización errática
Recomendaciones de entrevista:
- Pregunta: “Contame sobre una vez que tuviste 10 prioridades urgentes. ¿Cómo decidiste qué hacer primero?”
- Pregunta: “¿Cómo te asegurás de que lo que prometes se entregue a tiempo?”
- Red flag si responde: “Me enfoco en muchas cosas a la vez” (confirma C bajo)
Si avanza:
- Asignar mentor con alto C (engineering lead) para compensar
- Definir OKRs semanales (estructura externa que compense C bajo)
- Tracking explícito de commitments
COMPARACIÓN CON TU TOP PERFORMER ACTUAL: Tu mejor PM tiene C=82 vs este candidato C=45. Esa diferencia de 37 puntos explica por qué uno ship features 2x más rápido con menos sorpresas.
Pero este candidato tiene ER=85 (vs tu PM con ER=60). Mejor para customer discovery y evangelismo con stakeholders.
DECISIÓN SUGERIDA: ✅ Avanzar SI podés darle framework estructurado + mentor con alto C
❌ No contratar si esperás autonomía total en execution sin guardrails
Por qué esta diferencia:
✅ Contexto: Startup early-stage (no enterprise) ✅ Rol específico: PM (no “creative role” genérico) ✅ Benchmark interno: Compara con tu equipo actual ✅ Acción clara: Qué preguntar, cómo mitigar, qué estructura dar ✅ Trade-off explicado: ER alto puede compensar C bajo ✅ Decisión binaria: Contratar o no, con condiciones
Show Value, Not Secrets
Pregunta obvia: “¿Por qué no me decís exactamente cómo lo hacés?”
Respuesta honesta: El cómo es IP (prompts, training data, arquitectura del modelo). El qué es transparente (mejores decisiones, menos bias, contexto real).
Analogía
No necesitás saber cómo funciona el motor de un auto para evaluar si te lleva más rápido que otro. Lo que importa es:
- ¿Llego más rápido?
- ¿Es más seguro?
- ¿Gasto menos combustible?
Lo mismo con IA especializada.
Lo Que SÍ Mostramos
✅ Results: Comparaciones side-by-side (como la de arriba)
✅ Methodology overview: Domain training + feedback loops + contextual adaptation
✅ Customization options: Cómo adaptamos la IA a tu organización
✅ Bias mitigation: Cómo evitamos perpetuar sesgos históricos
Lo Que NO Revelamos
❌ Prompts específicos
❌ Training data details
❌ Model architecture
❌ Fine-tuning techniques
Por Qué Esto Es Ético
Competencia sana es sobre resultados, no copiar técnicas. Apple no revela cómo funciona el chip M3, pero podés medir que tu MacBook es más rápido.
Nosotros no revelamos nuestros prompts, pero podés comparar nuestros reportes con ChatGPT y ver la diferencia.
Implementación Práctica: Cómo Funciona en Tu Proceso
Paso 1: Define Tu Contexto Organizacional
Cuando empezás con Talen.to, definimos juntos:
- Industry: Tech, finance, healthcare, etc.
- Stage: Startup early-stage, scale-up, enterprise
- Cultura: Innovación vs estabilidad, autonomía vs estructura
- Valores: Top 3-5 valores no-negociables
Esto calibra la IA a tu realidad.
Paso 2: Benchmarks Internos
Evaluamos tus top performers actuales:
- ¿Qué OCEAN profiles tienen?
- ¿Qué dimensiones predicen éxito en tu org?
- ¿Qué trade-offs funcionan para vos?
La IA aprende tus patterns específicos.
Paso 3: La IA Se Adapta Con el Tiempo
Con cada evaluación:
- Aprende qué profiles funcionan mejor
- Refina sus recomendaciones
- Mejora la precisión de fit score
Ejemplo: Descubrís que en tu equipo, desarrolladores con E=40-55 retienen mejor que E=75-85 (porque valorás deep work). La IA aprende esto y ajusta sus análisis futuros.
Paso 4: Reportes Cada Vez Más Precisos
Después de 20-30 evaluaciones, los reportes mencionan:
- “Comparado con tu top 10% performers…”
- “En tu industria, este profile correlaciona con…”
- “Basado en tus últimos 12 hires, este score sugiere…”
Es IA personalizada para tu caso, no genérica.
Red Flags vs Green Flags: Cómo Evaluar “IA” en Otros Tools
🚩 Red Flags de IA Genérica
❌ “Powered by GPT-4” sin explicar qué hace diferente
❌ No mencionan domain training o fine-tuning
❌ Análisis idénticos para diferentes roles/industrias
❌ No ofrecen customization por organización
❌ No piden contexto (industry, stage, cultura)
❌ Reportes genéricos sin benchmarks relevantes
✅ Green Flags de IA Especializada
✅ Menciona training específico del dominio
✅ Pide contexto organizacional antes de analizar
✅ Reportes referencian tus benchmarks internos
✅ Se adapta con feedback (aprende de tus outcomes)
✅ Explica metodología sin revelar secrets
✅ Ofrece comparaciones contextuales (no absolutas)
Pregunta clave para cualquier vendor de “AI-powered” tools:
“¿Tu IA está entrenada específicamente para [tu dominio], o es ChatGPT/Claude con un prompt?”
Si dudan, es la segunda opción.
El Futuro (No Tan Lejano)
Hacia Dónde Va Esto
Hoy (2026):
IA interpreta OCEAN scores y genera insights contextuales
2027:
IA predice success likelihood en tu organización específica (basada en historical data de tus hires)
2028:
IA detecta early warning de attrition (fit decay over time — cuando el OCEAN profile del empleado deja de alinear con la cultura evolutiva de tu org)
2029:
IA sugiere internal mobility antes de que el empleado busque afuera (identifica roles internos mejor aligned con su perfil actual)
Por Qué Domain Expertise Será Aún Más Crítico
A medida que hay más data:
- Patterns se vuelven más complejos
- IA general no podrá competir con IA especializada
- “Winner takes most” en cada vertical (psychometrics, legal, medical, etc.)
La Ventaja de Arrancar Ahora
Cada evaluación que hacés:
- Mejora el modelo (feedback loop)
- Genera network effects (más clientes = mejor IA para todos)
- First-mover advantage en LATAM
Cuanto antes empieces, más ventaja acumulas.
Conclusión: IA Como Ferrari vs Fórmula 1
No todos los “AI-powered tools” son iguales.
Usar IA genérica para psychometrics es como competir en Fórmula 1 con un Ferrari de calle. Ambos son rápidos. Pero uno está optimizado específicamente para la pista.
Pregunta Clave para Vendors
“¿Tu IA está entrenada específicamente para psychometrics, o es ChatGPT con un prompt?”
Si no pueden responder claramente, ya tenés tu respuesta.

Próximos Pasos
Probá la Diferencia
Evaluá 3 candidatos con Talen.to y compará los reportes con cualquier tool genérico (o ChatGPT directo).
La diferencia es obvia en el primer reporte.
Descargá: Checklist de 10 Preguntas para Evaluar IA en Hiring Tools
PDF gratuito con las preguntas exactas que deberías hacer a cualquier vendor que dice usar “IA”.
¿Preguntas sobre cómo funciona nuestra LLM personalizada? Escribime a clara@talen.to

Artículos Relacionados

Cómo ChatGPT Cambió el Hiring (Y Qué Hacer al Respecto)
El impacto real de la IA generativa en reclutamiento y las estrategias para adaptarse en 2025.

Adaptabilidad: La Competencia #1 que Define el Éxito en 2025
Por qué los empleados más valiosos ya no son los más experimentados, sino los más adaptables.

IA-Ready Hiring Playbook: 11 Prácticas para Contratar en 2025
El playbook completo que usan +500 empresas para contratar talento preparado para la era de la IA.